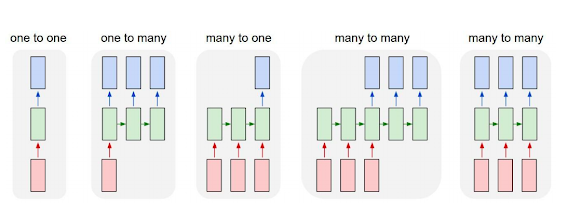
Auto Encoder

Auto - Encoder Principal Component Analysis Principal Component Analysis is uses to reduce the dimensions. PCA tries to find out important set of features to get the perfect decision boundary. Auto Encoder also does the same but in terms of features. Also if the data is too complex Auto-encoder is preffered over PCA Auto-encoder takes raw data like image as input and creates a vector representation of it using real numbers. What are the usual properties of the vector? 1. This should represent important features/attributes of the raw data with a numerical value. That is every element of this vector represents one or more significant attributes of raw data. These numbers are used to assign numbers to attributes 2. It should be automatically created or generated by a neural network. Neural Network can be simple Multi Layer Preceptron for simple data or Convolution Neural Network for image data o...