Recurrent Neural Network(RNN Part-2)
Different RNN Models
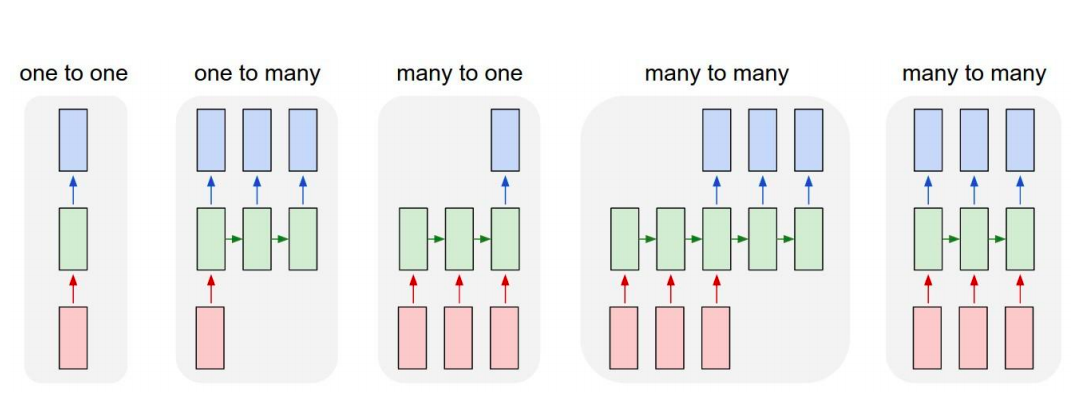
Many to one
We take only the LAST output of RNN
- Sentence Classification (Toxic Comment Classification)
- Image Classification
- Anomaly Detection
Many to Many
- We take all the output of RNN
- POS tagging of sentence
- Video Frame Classification
- Next Word Prediction
RNN Example
- Task - C Class POS Tagging
- Input - 1 x T x F ○ T = 4 : Timesteps ○ F = Number of features (?)
- Target - 1 x T x C ○ C = Number of classes (?)

RNN Limitations
Vanishing / Exploding Gradient Problem
- In forward pass output of one Timestep (t) is fed to the next Timestep (t+1)
- At any Timestep (t) is the trainable weights are same
- At any Timestep (t) is the input is different
- In backward pass (Backpropagation through time) we move from (t+1) to t
- Due to chain rule of gradients are multiplied
- What if gradient at one Timestep (t) is very small - Vanishing Gradient
- What if gradient at one Timestep (t) is very large - Exploding Gradient

Long Short Term Memory LSTM
Input gate: contribution of input
Output gate: contribution to output
Reset gate: what to forget
Proposal gate: what to remember ? Proposes new state

Equation Require 2 Weight Metrics for W and U for EACH of the functions
RNN/LSTM Implementation Guide
RNN Equation Input Data Shape : 1 x T x F (T= Timesteps F = Number of Features)
- For a single Hidden Layer RNN with D Nodes (POS Tagging problem)
- X = Array of shape [1 , T, F]
- Y = Array of shape [1 , T, C]
- W1 = Array of shape [F , D], U1 = Array of shape [D , D]
- W2 = Array of shape [D , C],
- For t in 1...T ○ Y(t) = MATMUL(X(t),W1) + MATMUL(Y(t-1),U1)
- Y2 = MATMUL(Y,W2) # Y = Array of shape [1 , T , D] Target Data Shape : 1 x T x C (C = Number of Classes) usually one hot encoded



Comments
Post a Comment