Introduction to Machine Learning (part-5)
Data Mining : It defined as a process used to extract usable data from a larger set of any raw data. It implies analyzing data patterns in large batches of data using one or more software.
Crisp-dm known for Cross-Industry Standard process for Data Mining. Aim is to develop a tool and application neutral process for conducting data mining and define tasks, outputs from these tasks, terminology and mining problem type characterization. It has four level of abstraction :
- Phases
- Generic Tasks
- Specialized Task
- Process Instance
Data Mining Context : In data mining the context is defined by four dimensions
- Application domain: Medical Prognosis.
- Data Mining Problem Type: Regression.
- Technical Aspect: Censored Observations.
- Tools and Techniques: Cox’s Regression, CIL’s GENNA.
Phases of Crisp-dm :
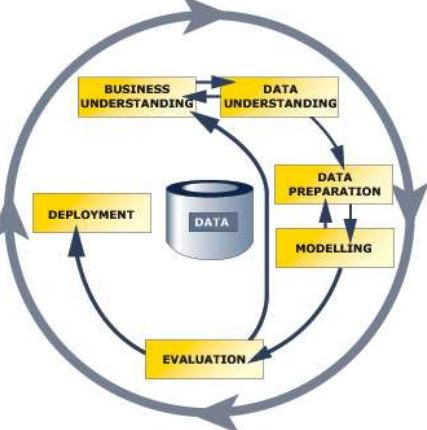
It is non - linear, there is repeatedly backtracking.
Business Understanding Phase:
- Understand the business objectives It need to understand the business objective, the business process ,cost/benefit analysis.
- Current Systems Assessment : Identify the key actors, minimum the Sponsor and the Key User, What forms should the output take? , Integration of output with existing technology landscape and Understand Market norms and standards.
- Task Decomposition : Break down the objective into sub-tasks and Map sub-tasks to data mining problem definitions
- Identify Constraints : Resources and Law e.g. Data Protection
- Build a project plan :List assumptions and risk (technical/financial/business/ organisational) factors.
- Collect Data : Internal and External Sources (e.g. Axiom, Experian), Document reasons for inclusion/exclusions, Depend on a domain expert and Accessibility issues.
- Data Description : Document data quality issues, requirements for data preparation and Compute basic statistics.
- Data Exploration : Simple univariate data plots/distributions,Investigate attribute interactions and Data Quality Issues.
- Integrate data: Joining multiple data tables and Summarisation/aggregation of data.
- Select Data : Attribute subset selection : Rationale for Inclusion/Exclusion and Data sampling : Training/Validation and Test sets.
- Data Transformation : Using functions such as log , Factor/Principal Components analysis and Normalization/Discretisation.
- Clean Data : Handling missing values/Outliers.
- Data Construction : Derived Attributes.
The Modelling Phase:
- Select of the appropriate modelling technique: Data pre-processing implications on attribute independence and Data types/ Normalisation/ Distributions.It is dependent on Data mining problem type and Output requirements.
- Develop a testing regime : By sampling,Verify samples have similar characteristics and are representative of the population.
- Build Model : Choose initial parameter settings and Study model behavior.
- Assess the model : Beware of Over-fitting ,Investigate the error distribution , Identify segments of the state space where the model is less effective , Iteratively adjust parameter settings and then Document reasons of these changes.
The Evaluation Phase :
- Validate Model : Human evaluation of results by domain experts, Evaluate usefulness of results from business perspective, Define control groups, Calculate Lift curves and Expected Return on Investment.
- Review Process
- Determine next steps: Potential for deployment, Deployment architecture and Metrics for success of deployment.
The Deployment Phase :
- Knowledge Deployment is specific to objectives : Knowledge Presentation , Deployment within Scoring Engines and Integration with the current IT infrastructure - Automated pre-processing of live data feeds and XML interfaces to 3rd party tools , Generation of a report - Online/Offline and Monitoring and evaluation of effectiveness.
- Process deployment/productionisation
- Produce final project Report : Document everything along the way.



Comments
Post a Comment