Model Evaluation and Selection
Model Process :
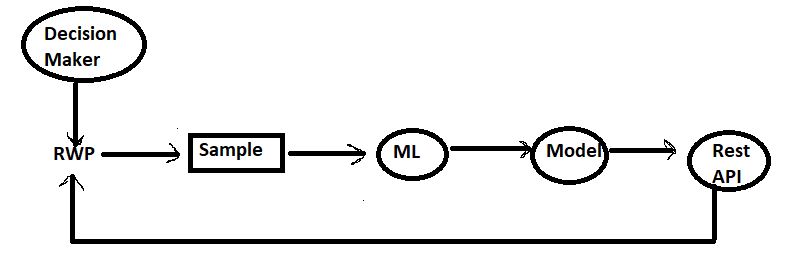
In decision maker process, we follow f : x → y and Real world process (RWP) tends to the population.
After building a model, we need to know, how accurate the model is expected to be on population. For that, here comes the Confusion Matrix

Here we are getting 88 out of 100 as correct, therefore the
Accuracy = 88/100 = 0.88
we need to check whether the accuracy will be fine for model, for that we check Expected Accuracy.
E[x] = Σx P(x)X
h(x(vector)) = y (Actual)
Goal to be achieved here is h(x(vector)) = f(x(vector)) for each x belongs to population.
h(x(vector)) = y , E [h(x(vector)) = f(x(vector))] for each x belongs to population.
Here, E[h(x(vector)) = f(x(vector))] says that how much we have predicted correctness on unseen data.
When we have data we split it into two categories :
- Training Data
- Test Data
Central Limit Theory : It allows to estimate the accuracy from the unseen data. If you have n (x,x,.......,x) random variables and they have mean and σ associated with it then
mean = θ
σ = θ (1- θ) / √n , where n is the size of the data.
Given we have normal distribution :

Zσ = 1.96
we took 95% because we are sure that our accuracy of model here lies between 0.768 and 0.832.
Therefore, the Confidence Interval , which defines the accuracy of model will be :
[0.768 , 0.832 ] = Confidence Interval
Accuracy for set of n random variables should be reported using Confidence Interval that is :
[ μ -zσ , μ + zσ]
where μ is Accuracy
and zσ is √Accuracy(1-Accuracy) / √n
Width of confidence interval depends on the Size of data


Comments
Post a Comment