Text Analysis (Part - 4)
The article covers a very important concepts of Text Analysis from Bayesian's i.e the Latent Dirichlet Allocation which is the part of topic modelling.
What is Topic Modelling?
Topic modelling is a type of statistical modelling for discovering the abstract “topics” that occur in a collection of documents. This can be useful for search engines, customer service automation, and any other instance where knowing the topics of documents is important. Thus, Topic Models, in a nutshell, are a type of statistical language models used for uncovering hidden structure in a collection of texts.
There are multiple methods of for topic modelling and one of them includes Latent Dirichlet Allocation (LDA).
Latent Dirichlet Allocation
Latent Dirichlet Allocation (LDA) is an example of topic model and is used to classify text in a document to a particular topic. It builds a topic per document model and words per topic model, modelled as Dirichlet distributions.
Basic Idea
LDA is a generative probabilistic model that assumes each topic is a mixture over an underlying set of words, and each document is a mixture of over a set of topic probabilities. It is a form of unsupervised learning that views documents as bags of words (discussed earlier). LDA makes a key assumption that the document was generated by picking a set of topics and then for each topic picking a set of words.
The topics are then found by reverse engineering the above process. To do this LDA does the following for each document m.
- Assuming that there are k topics across all of the documents
- These k topics are distributed across document m (this distribution is known as α and can be symmetric or asymmetric (described later)) by assigning each word a topic.
- For each word w in document m, it is assume that its topic is wrong but every other word is assigned the correct topic.
- For each word w a topic is assigned using probability, this is based on two things:
2. How many times word w has been assigned a particular topic across all of the documents (this distribution is called β(discussed later))
- This process is repeated number of times for each document
Parameters of LDA
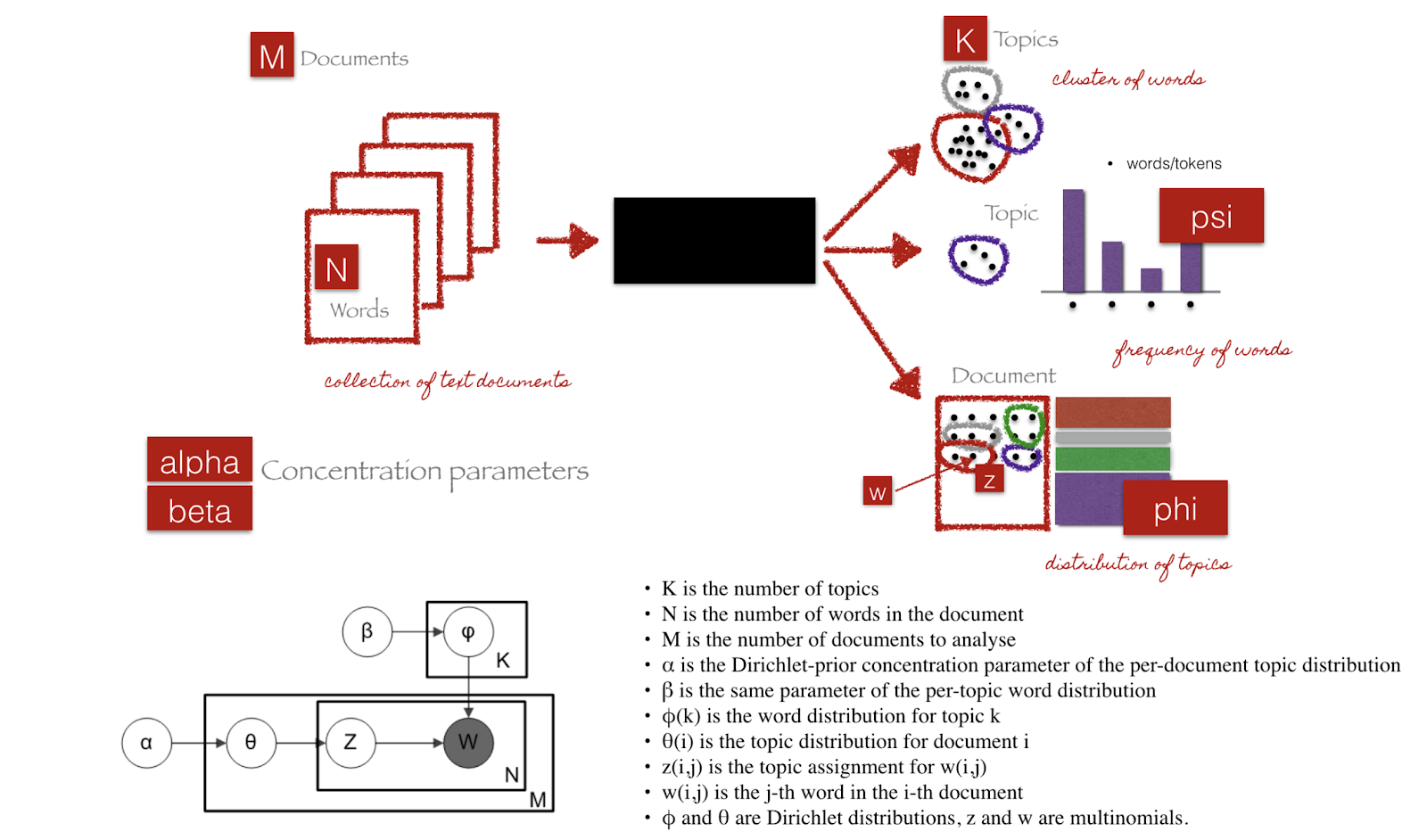
In the above figure:
psi is the distribution of words for each topic K
phi is the distribution of topics for each document i
β is the per-topic word distribution,
θ is the topic distribution for document m,
φ is the word distribution for topic k,
z is the topic for the n-th word in document m, and
w is the specific word
Mathematics In LDA
What LDA says is that each word in each document comes from a topic and the topic is selected from a per-document distribution over topics. So we have two matrices:
- ϴtd = P(t|d) which is the probability distribution of topics in documents
- Фwt = P(w|t) which is the probability distribution of words in topics
And, we can say that the probability of a word given document i.e. P(w|d) is equal to:

where t is the total number of topics and w number of words in our vocabulary for all the documents.
Assuming the conditional independence, we have
P(w|t,d) = P(w|t)
And hence P(w|d) is equal to:

that is the dot product of ϴtd and Фwt for each topic t.
This can be represented in the form of a matrix as:

So, looking at this we can think of LDA similar to that of matrix factorisation or Single Value Decomposition (SVD, discussed earlier), where we decompose the probability distribution matrix of word in document in two matrices consisting of distribution of topic in a document and distribution of words in a topic.



Comments
Post a Comment