Convolutional Neural Networks(Part-4)
AlexNet
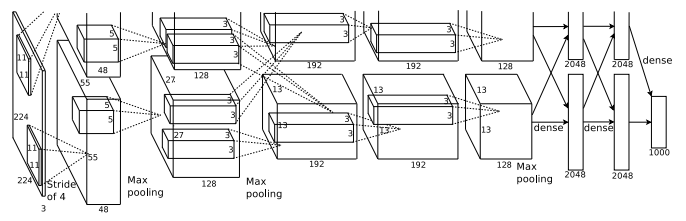
AlexNet is considered to be the first paper/ model which rose the interest in CNNs when it won the ImageNet challenge in 2012. AlexNet is a deep CNN trained on ImageNet and outperformed all the entries that year. It was a major improvement with the next best entry getting only 26.2% top 5 test error rate. Compared to modern architectures, a relatively simple layout was used in this paper.
ZFNet
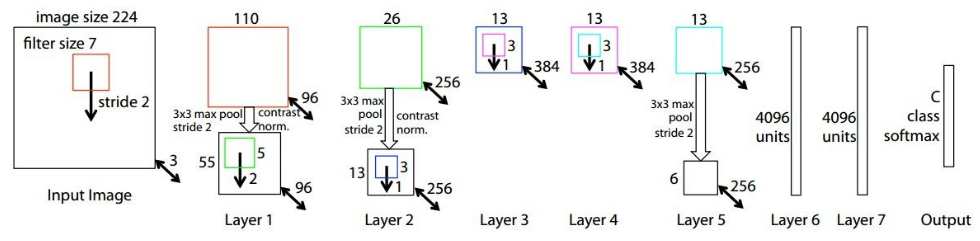
ZFNet is a modified version of AlexNet which gives a better accuracy. One major difference in the approaches was that ZFNet used 7x7 sized filters whereas AlexNet used 11x11 filters. The intuition behind this is that by using bigger filters we were losing a lot of pixel information, which we can retain by having smaller filter sizes in the earlier conv layers. The number of filters increase as we go deeper. This network also used ReLUs for their activation and trained using batch stochastic gradient descent.
GoogLeNet
In the Inception module 1×1, 3×3, 5×5 convolution and 3×3 max pooling performed in a parallel way at the input and the output of these are stacked together to generated final output. The idea behind that convolution filters of different sizes will handle objects at multiple scale better.

The overall architecture is 22 layers deep. The architecture was designed to keep computational efficiency in mind. The idea behind that the architecture can be run on individual devices even with low computational resources. The architecture also contains two auxiliary classifier layer connected to the output of Inception and Inception layers.
The architectural details of auxiliary classifiers as follows:
- An average pooling layer of filter size 5×5 and stride 3.
- A 1×1 convolution with 128 filters for dimension reduction and ReLU activation.
- A fully connected layer with 1025 outputs and ReLU activation
- Dropout Regularization with dropout ratio = 0.7
- A softmax classifier with 1000 classes output similar to the main softmax classsifier.
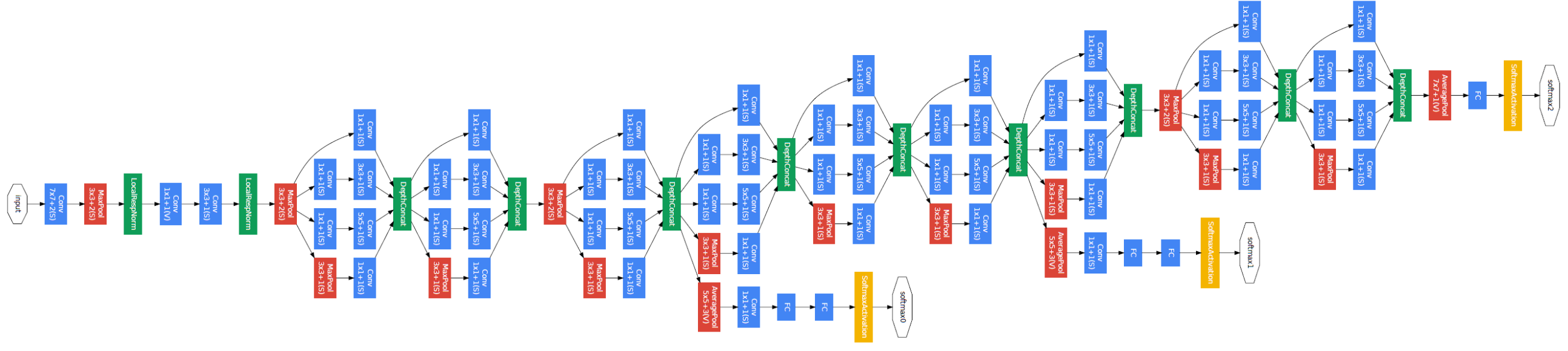
This architecture takes image of size 224 x 224 with RGB color channels. All the convolutions inside this architecture uses Rectified Linear Units (ReLU) as their activation functions.
ResNet

Comments
Post a Comment